软统迭代二文档
JClassDiagram 迭代二设计文档(第95组)
团队介绍
| 姓名 | 学号 | QQ号 | 职责 |
|---|---|---|---|
| 卞浩宇 | 221098106 | 3255698603 | 撰写文档 |
| 翟志阳 | 221250161 | 3056593724 | 撰写文档 |
| 周屿杨 | 221870148 | 3591599547 | 撰写代码 |
| 顾益铭 | 221250142 | 2408985579 | 撰写文档 |
项目目标
在迭代二中,进一步完善类图解析工具,增强对复杂 Java 元素(泛型、容器、数组、抽象类及枚举)的规范化处理能力,并实现关联与依赖关系的粗略分析。
同时,设计并实现三类基于类图的代码质量分析器,支持检测类规模异常(过大/过小类、数据类)、继承结构缺陷及循环依赖问题,最终输出符合 PlantUML 规范的文本形式类图和代码质量分析报告。
系统设计
总体设计
系统主要分为主程序模块和测试模块,主程序模块负责核心功能实现,测试模块用于验证主程序功能的正确性和稳定性。
主要模块及关系
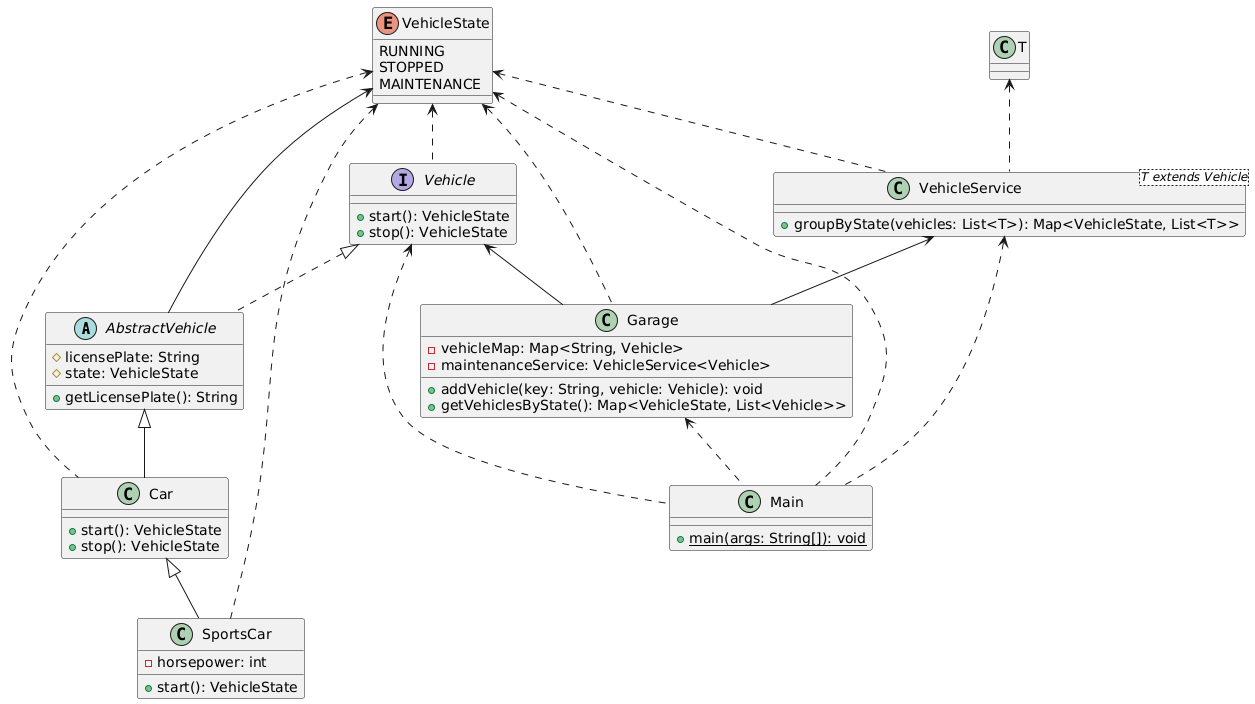
主程序模块(main/java)
Main.java:作为程序的入口,负责启动整个系统,协调各功能模块完成类图生成等核心任务。diagram包:AccessModifier.java:用于定义和处理类、方法、字段等的访问修饰符。ClassDiagram.java:表示类图这一数据结构,包含类、接口、关系等元素。ClassDiagramGenerator.java:核心生成器,根据输入的 Java 文件,分析并生成类图。EnumConstantInfo.java:存储枚举常量的相关信息。FieldInfo.java:存储类的字段信息,如字段名、类型等。MethodInfo.java:存储类的方法信息,如方法名、参数、返回值等。ParameterInfo.java:存储方法参数的详细信息。Relationship.java:表示类与类、类与接口之间的关系。RelationshipType.java:定义关系的类型,如继承、实现等。TypeInfo.java:存储类型信息,如类、接口的类型。
测试模块(test)
test/java包:lab1子包:包含多个测试类,对主程序在基础场景下的功能进行测试,如单类、多类、关系等测试。lab2子包:包含更复杂场景的测试类,如类分析、复杂关系、依赖分析等测试。
test/resources包:lab1子包:提供基础测试用的 Java 文件,为lab1子包的测试类提供数据。lab2子包:提供复杂测试用的 Java 文件,为lab2子包的测试类提供数据。
模块关系
Main.java调用diagram包中的类来完成类图的生成工作。test/java包中的测试类调用main/java中的类进行功能测试,验证其正确性。test/resources包中的 Java 文件为test/java包中的测试类提供测试数据。
图形描述
1 | |
类设计
系统主要类及其关系
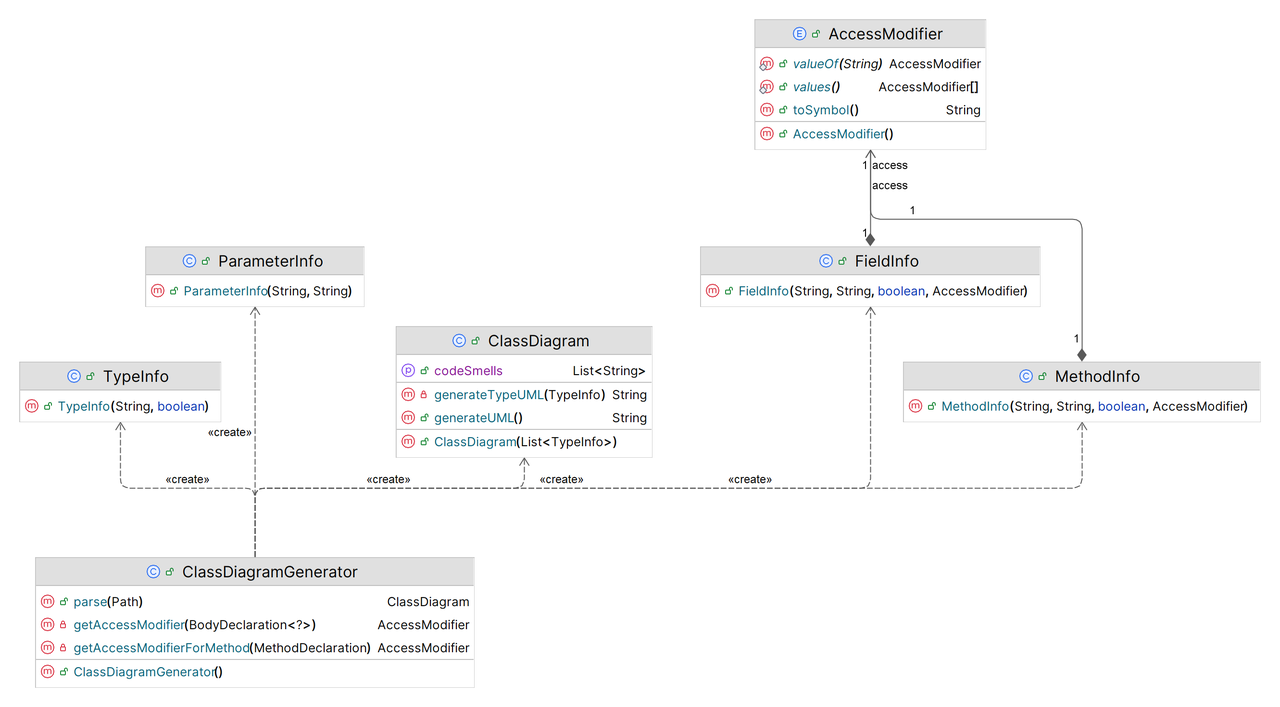
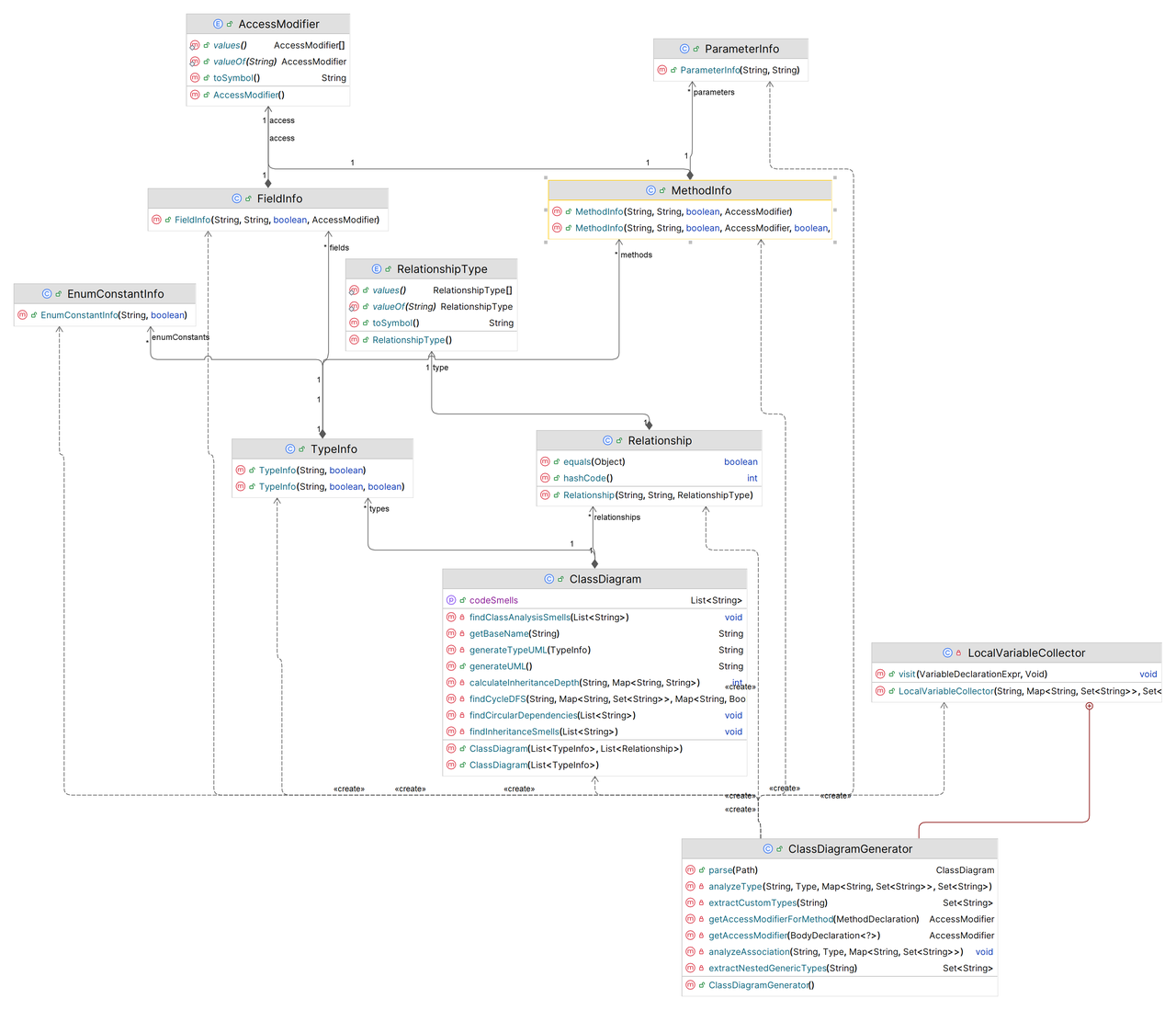
设计说明
设计模式(迭代一)
-
访问者模式(Visitor Pattern)
-
体现在
ClassDiagramGenerator类中,它通过遍历 Java 源代码的 AST(抽象语法树)来访问不同类型的节点(类、接口、方法、字段等)。 -
这种模式使得添加新的访问操作变得容易,而不需要修改现有的类结构。
-
-
组合模式(Composite Pattern)
-
体现在类型信息的组织上,
TypeInfo包含了FieldInfo、MethodInfo等子组件。 -
这种结构使得可以统一处理复杂对象和简单对象。
-
-
策略模式(Strategy Pattern)
-
体现在访问修饰符的处理上,通过
AccessModifier枚举和不同的访问修饰符处理策略。 -
使得可以灵活地改变访问修饰符的处理方式。
-
设计模式(迭代二)
-
访问者模式(Visitor Pattern)
-
在
ClassDiagramGenerator中使用了LocalVariableCollector作为访问者来收集局部变量信息。 -
通过继承
VoidVisitorAdapter实现,用于遍历 AST(抽象语法树)。
-
-
工厂模式(Factory Pattern)
-
ClassDiagramGenerator作为工厂类,负责创建ClassDiagram对象。 -
通过
parse方法封装了复杂的对象创建过程。
-
-
组合模式(Composite Pattern)
-
在类图结构中,
TypeInfo、FieldInfo、MethodInfo等类形成了组合结构。 -
允许统一处理单个对象和组合对象。
-
系统扩展性设计
-
模块化设计
-
核心类职责明确:
-
ClassDiagram: 负责 UML 图的生成和代码异味检测。 -
ClassDiagramGenerator: 负责解析 Java 源代码。 -
TypeInfo: 存储类型信息。 -
Relationship: 处理类之间的关系。
-
-
-
可扩展的数据结构
-
使用枚举类型
RelationshipType定义关系类型,便于添加新的关系类型。 -
AccessModifier枚举处理访问修饰符,支持扩展新的访问级别。
-
-
代码异味检测框架
-
getCodeSmells()方法提供了可扩展的代码异味检测框架。 -
分别实现了类分析、继承分析和循环依赖检测。
重要类/接口详细介绍
-
ClassDiagram 类:
1
2
3
4
5
6
7
8
9
10
11public class ClassDiagram {
private List<TypeInfo> types;
private List<Relationship> relationships;
主要方法:
- generateUML(): 生成UML图
- getCodeSmells(): 检测代码异味
- findClassAnalysisSmells(): 分析类级别的代码异味
- findInheritanceSmells(): 分析继承相关的代码异味
- findCircularDependencies(): 检测循环依赖
} -
ClassDiagramGenerator 类:
1
2
3
4
5
6
7
8
9
10public class ClassDiagramGenerator {
private static final Set<String> BASIC_TYPES;
private static final Set<String> CONTAINER_TYPES;
主要方法:
- parse(Path sourcePath): 解析Java源代码文件
- analyzeAssociation(): 分析类之间的关联关系
- analyzeType(): 分析类型依赖
- extractCustomTypes(): 提取自定义类型
}
系统扩展建议
-
关系类型扩展
-
可以通过扩展
RelationshipType枚举来支持更多的 UML 关系类型。 -
在
generateUML()方法中添加相应的处理逻辑。
-
-
代码异味检测扩展
-
可以添加新的检测方法,如
findMethodSmells()、findFieldSmells()等。 -
实现新的检测规则,如方法复杂度、参数数量等。
-
-
输出格式扩展
-
可以添加新的输出格式支持,如 JSON、XML 等。
-
实现新的生成器类,如
JSONDiagramGenerator、XMLDiagramGenerator等。
-
-
语言支持扩展
-
可以添加对其他编程语言的支持。
-
实现新的解析器,如
PythonDiagramGenerator、CSharpDiagramGenerator等。
-
数据结构与算法设计
关键算法设计
泛型与容器类型提取
为了正确处理泛型参数和容器类型,系统设计了 extractCustomTypes 方法对类型字符串进行解析。从类型表示中移除数组符号([]),然后检查基本类型集合(如int, String等)来跳过原生类型。接下来,提取类型字符串中主类型名称(若包含泛型尖括号,则取尖括号前部分)。如果主类型不是预定义的容器类(如List, Map等),则将其视为自定义类型加入结果。若类型含有泛型参数,则进一步解析尖括号内的内容:利用正则表达式匹配所有泛型参数中的类型标识符,过滤出非基本类型且非容器类型的名称加入结果。该方法通过递归处理嵌套泛型结构 ,确保无论是简单类型、泛型嵌套还是容器嵌套,都能提取出其中引用的自定义类型。例如,对于类型 List<Map<String, CustomType>>,解析后会提取出 CustomType 作为自定义类型,而不会错误地将 List 或 Map 当作关联关系。
关联与依赖关系分析
类图生成过程中,系统对每个类的字段和方法进行扫描,分别收集“关联关系(Association)”和“依赖关系(Dependency)”。关联关系表示类的拥有关系(通常由属性成员产生),依赖关系表示类的使用关系(通常由方法参数、返回值或局部变量产生)。算法实现上,针对每个字段,调用 analyzeAssociation(sourceClass, fieldType, associationsMap):该函数对字段类型字符串调用 extractCustomTypes 提取所有自定义类型,并将它们记录为当前类的关联目标(忽略来源类自身的类型以避免自关联)。方法部分则使用 analyzeType(sourceClass, someType, dependenciesMap, sourceAssociations):对方法返回值类型、每个参数类型,以及方法体内的本地变量类型执行类似解析。不同的是,在记录依赖关系时会避开已存在的关联关系(因为如果某类型已经作为属性出现过,则应视为关联而非依赖)。通过这两个分析过程,系统分别构建了 associations 和 dependencies 映射表,用于稍后生成关系连线。当解析完所有类型后,程序会遍历这两个映射,将其中的条目转化为 Relationship 对象列表:对于每个关联关系,添加 “target <-- source”的关系;对于每个依赖关系,则添加“target <.. source”的关系(但需排除已被标记为关联的情形)。这样就实现了关联和依赖的初步区分:例如,类 A 持有类 B 的实例作为字段,则记为 A 与 B 的关联;类 C 在方法参数或返回值中用到了类 D,则记为 C 依赖于 D。
代码异味检测(God Class, Lazy Class, Data Class)
迭代二扩展了类图工具,增加对三种经典代码异味的检测功能。**God Class(上帝类)**指过度庞大的类。实现中简单采用字段数或方法数的阈值判断:若一个非接口非枚举的类字段数量
继承结构分析(Too Many Children, Inheritance Abuse)
除了单个类的规模问题,系统还分析了类之间的继承层次结构以发现潜在问题。首先,类图生成完毕后,工具会构建一个继承关系映射:遍历所有非接口非枚举的类,初始化每个类名对应一个子类列表;然后再次遍历这些类型,查找每个类的父类,如果存在继承则将子类登记到父类名的子类列表中。由此可以统计每个类的直接子类数量以及计算继承深度。Too Many Children 检测通过遍历上述子类列表映射,检查任何一个父类名下的直接子类数量是否达到阈值(例如 <|-- 串联,记录为“Inheritance Abuse: 类A <|-- 类B <|-- ... <|-- 类N”这样的提示。这一检测有助于发现过深的继承层次可能导致的设计僵化问题。
循环依赖检测
为捕获模块间循环依赖风险,迭代二实现了基于图遍历的循环依赖检测算法。工具将先前收集的所有关联和依赖关系视为有向图的边,构造一个依赖图数据结构(邻接表):图中的节点是所有类型名称(使用类型基本名,即去除泛型标记后的名称)。初始化时先将每个类型加入图的节点集,确保没有解析遗漏。然后遍历关系列表,对于每一条依赖或关联关系,在图中添加一条从源类型指向目标类型的有向边(表示“源类依赖/关联目标类”)。构造完成后,采用深度优先搜索(DFS)算法来寻找环路:维护一个全局访问标记 map 和一个当前递归路径列表。对每个尚未访问的节点调用递归 DFS 方法 findCycleDFS,在 DFS 过程中,沿着依赖边向下探索。如果遇到已访问节点,检查其是否在当前递归路径中;若是,则从该节点在路径中的位置截取出一条完整的循环路径,并将循环各节点名称连接成提示字符串,如“Circular Dependency: A <. B <. C <. A”。一旦找到一个循环,算法即可终止进一步搜索(当前实现找到第一环路后跳出)。这种 DFS 找环的方法可以有效发现类之间直接或间接的循环引用,为用户提供架构上的警示。
数据结构设计
核心模型类
本系统采用分层的数据模型来表示解析得到的类图元素,每种元素对应一个信息类:
- TypeInfo:表示一个类型(类/接口/枚举)的信息,包含字段:
name:类型名称(包括泛型参数表示,如ClassA<T>),用于输出展示。isInterface:是否为接口类型。isAbstract:是否为抽象类(仅对类有效,接口默认抽象不使用此标志)。isEnum:是否为枚举类型。fields:该类型的字段列表,元素类型为FieldInfo。methods:该类型的方法列表,元素类型为MethodInfo。enumConstants:枚举常量列表,元素类型为EnumConstantInfo(非枚举类型该列表为空)。superClass:父类名称(字符串,类继承关系,仅类有值)。implementedInterfaces:实现的接口名称列表(仅类有值,接口的该列表为空)。extendedInterfaces:继承的父接口列表(仅接口有值,类的该列表为空)。
- FieldInfo:表示一个字段的详细信息,包含:
name:字段名。type:字段类型名称(可能包含泛型,如List<String>)。isStatic:是否为静态字段。access:访问修饰符(枚举AccessModifier表示,如 PUBLIC/PROTECTED/...)。
- MethodInfo:表示一个方法的详细信息,包含:
name:方法名。returnType:返回类型名称。isStatic:是否为静态方法。isAbstract:是否为抽象方法。access:访问修饰符。genericParams:方法的泛型参数列表字符串表示(如果方法定义了泛型类型参数,则如<T, U>这样存储;否则为空字符串)。parameters:方法参数列表,元素类型为ParameterInfo,按声明顺序保存。
- ParameterInfo:表示方法的一个参数,包含
name参数名和type参数类型。 - EnumConstantInfo:表示枚举类型的一个常量,包含
name常量名和hasArguments是否带有初始化参数(用于区分输出时是否在常量后加上())。 - Relationship:表示两个类型之间的关系。包含
source源类型名、target目标类型名,以及关系类型type(枚举RelationshipType,可为 ASSOCIATION 或 DEPENDENCY)。在本设计中,为方便表示“源 -> 目标”的连线方向,我们将Relationship.source定义为关系箭头指向的一端,target为箭头起始端。例如,若类 A 关联类 B,则生成 Relationship 的source = B, target = A, type = ASSOCIATION,输出时呈现为A --> B的形式。
新增字段的作用
迭代二相对于迭代一在模型类中引入了若干新的字段,以支持对复杂 Java 元素的表示和分析需求:
-
在 TypeInfo 中新增了
isAbstract和isEnum字段,用于标识抽象类和枚举。isAbstract使我们在生成 UML 时可以加上“abstract”关键字修饰类声明;而isEnum则用于区别枚举类型,确保在输出时使用“enum”关键字并在类体内列出枚举常量。此外,TypeInfo 的name属性在创建时即考虑了泛型类型参数,如果类型声明包含泛型,则将参数列表附加于名称(例如ClassA<T>),这样可以在类图中直观地体现泛型。 -
在 MethodInfo 中新增了
isAbstract和genericParams字段。其中,isAbstract用于标记抽象方法(主要出现在抽象类或接口中),以便在生成类图文本时对抽象方法增加{abstract}标识,提高可读性。genericParams则保存方法的类型参数列表字符串,使得如果方法本身是泛型方法(例如public <T> void foo(T t)),我们也能在类图的方法签名中体现<T>。这些新增字段保证了对抽象及泛型的完整支持,避免信息丢失。 -
引入 EnumConstantInfo 类及在 TypeInfo 中的
enumConstants列表,是为了支持枚举类型的特殊结构。相比普通类,枚举需要存储其常量集合。通过将每个常量名和是否含参数打包成 EnumConstantInfo,我们可以在输出时逐行列出枚举常量,并针对带参数的常量添加一对括号,符合 Java 枚举语法习惯。这使得生成的类图对枚举的展示更规范易读。 -
Relationship 模型类在迭代二中也被引入,用于统一存储类与类之间的关联、依赖关系。相比迭代一直接在生成UML 时拼接关系字符串的做法,使用 Relationship 对象列表可以先行整理和去重关系,再在输出时统一处理符号表示(如
<--表示关联,<..表示依赖)。这提升了关系处理的清晰度,也方便后续对关系进行分析(例如循环依赖检测正是遍历 Relationship 列表构建图来实现)。 -
类型扩展的支持方式:数据结构的设计使系统具备一定的扩展弹性来应对泛型、容器和枚举等复杂类型:
- 泛型类型:采用在名称和专有字段中存储泛型信息的方式。
TypeInfo.name保留类声明的泛型参数语法,以确保类图中类型定义完整;MethodInfo.genericParams保存方法声明的泛型参数。对于字段和参数的类型,由于直接存储字符串即可包含泛型信息(如"List<CustomType>"),因此FieldInfo.type和ParameterInfo.type已经天然支持泛型表示。extractCustomTypes算法则负责从这些字符串中提炼出基础的自定义类型名,用于关系分析,不受具体泛型符号干扰。这种处理方式相对简洁地扩展了对泛型的支持。 - 容器与数组:容器类被视为特殊的泛型,其类型参数内的自定义类型会被提取而容器本身不计入关联/依赖关系。通过在 CONTAINER_TYPES 集合列出常见容器名(如 List, Map 等),
extractCustomTypes能识别这些容器并跳过将它们加入关系,只提取其中承载的元素类型作为关联或依赖。例如字段类型为ArrayList<Foo>时,关系只会记录对Foo的关联而不会记录ArrayList。数组则通过简单去除[]后按元素类型处理,实现上与泛型提取共享逻辑。因此,无论是Bar[]还是List<Bar>,最终都能正确提取出Bar这个自定义类型用于关系分析。 - 抽象类与接口:数据结构本身区分了抽象类(isAbstract)和接口(isInterface),这在算法中主要影响输出和某些检测。例如接口的方法在解析时被统一标记为 public(Java接口默认 public),即通过
getAccessModifierForMethod策略保证接口中方法的访问修饰符正确设定。抽象类和接口在代码异味检测中被跳过了部分规则(如不参与God Class/Lazy Class判定),也是利用这些标志位实现的。这样保证了模型对这些特殊类型的恰当处理。 - 枚举类型:通过
TypeInfo.isEnum标识,配合 enumConstants 列表,系统能够在保持与类相同结构的同时,特殊对待枚举的内容解析和输出。在解析阶段,对 EnumDeclaration 会新建 TypeInfo 并设isEnum=true,然后提取枚举常量加入 enumConstants;同时枚举的字段和方法依然作为常规 FieldInfo、MethodInfo 处理,以复用已有逻辑。输出时则根据 isEnum 决定使用enum 名称 { ... }语法,并在花括号内首先列出所有枚举常量,再列出字段和方法。这种适配方式使得无需为枚举单独定义复杂模型,复用了大部分类的结构,又能正确表示枚举特有的信息。
- 泛型类型:采用在名称和专有字段中存储泛型信息的方式。
通过上述算法与数据结构设计,迭代二的类图解析工具可以支持更复杂的 Java 语言元素(泛型、容器、抽象类、枚举),并在此基础上增加关系分析和代码质量检测功能。关键算法保证了关联、依赖关系的合理提取和各类代码异味的识别;而健全的模型数据结构为信息的存储和输出提供了良好的组织,使系统具有较好的扩展性和维护性。
附录
实际工作安排
卞浩宇:文档撰写,数据结构与算法设计部分。
翟志阳:文档撰写,类设计部分与绘图。
周屿杨:Java 代码撰写。
顾益铭:文档撰写,总体设计部分、运行结果与格式汇总。
运行结果
1 | |